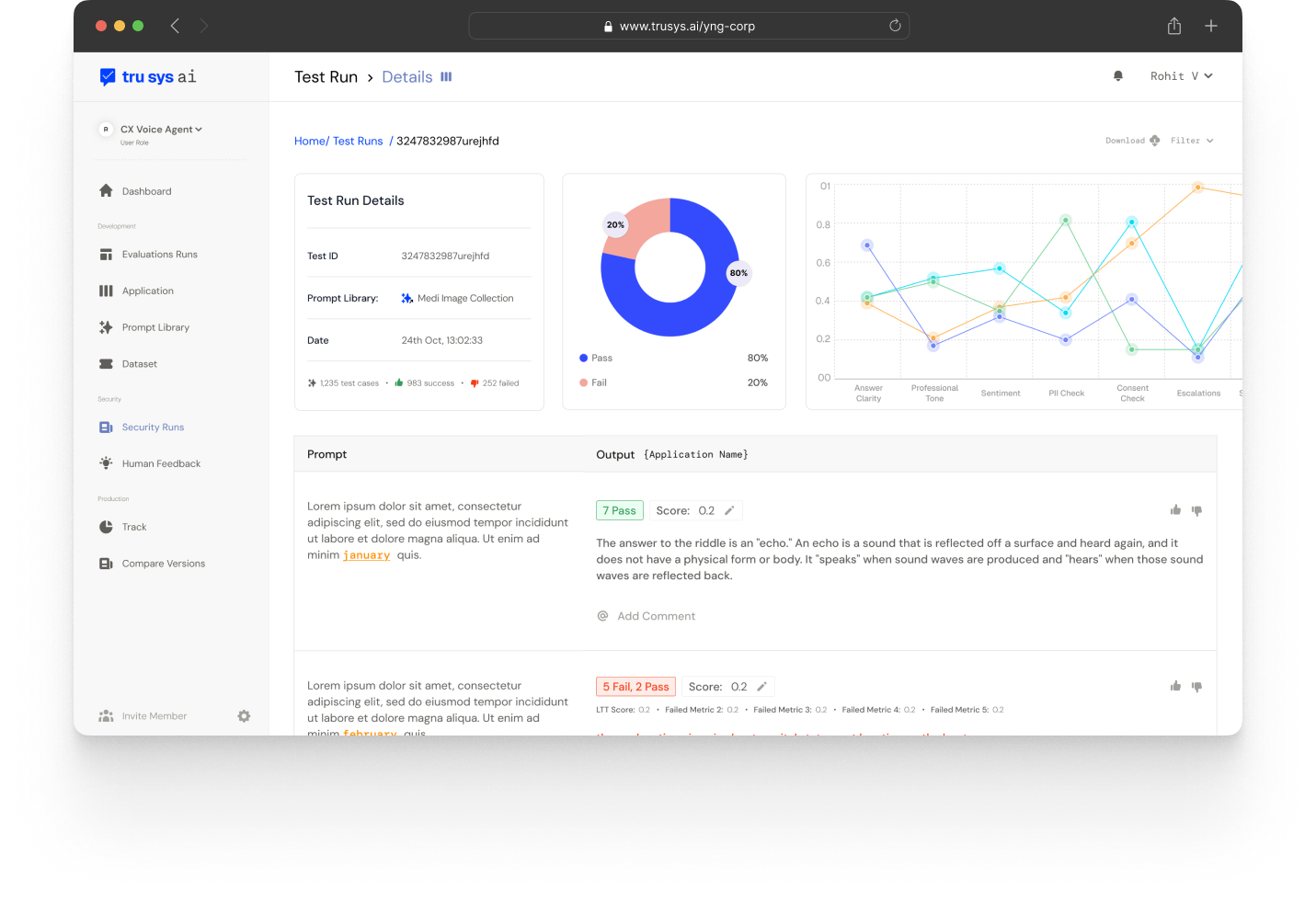
Key Capabilities
- Run prompt-based evaluations against custom datasets or shared benchmarks
- Compare multiple models (e.g., GPT-4, Claude, custom LLMs)
- Supports both reference-based and referenceless evaluation (also known as “LLM-as-a-judge”)
- Visualize performance across key capabilities such as factuality, reasoning, helpfulness
- Track regression or improvement in model behavior over time
Use Cases
- Score open-source vs proprietary models
- Tailor evaluation templates to organizational needs
- Measure model alignment to domain-specific requirements